
An uninitialized read in V8's Maglev JIT, and what made it a P2 instead of a vulnerability

TL;DR
MaglevGraphBuilder::SaveCallSpeculationScope is an RAII scope class that saves and restores two pieces of compiler state across a call-site inlining attempt: current_speculation_feedback_ and current_speculation_mode_. It saves and restores the first one correctly. It does not save the second one at all. The member saved_mode_ is declared, never initialized, and read in the destructor. Every Maglev compilation of a script that hits Function.prototype.call, Function.prototype.apply, an array iteration callback, new Array(), or instanceof reads uninitialized memory and writes that garbage back to current_speculation_mode_.
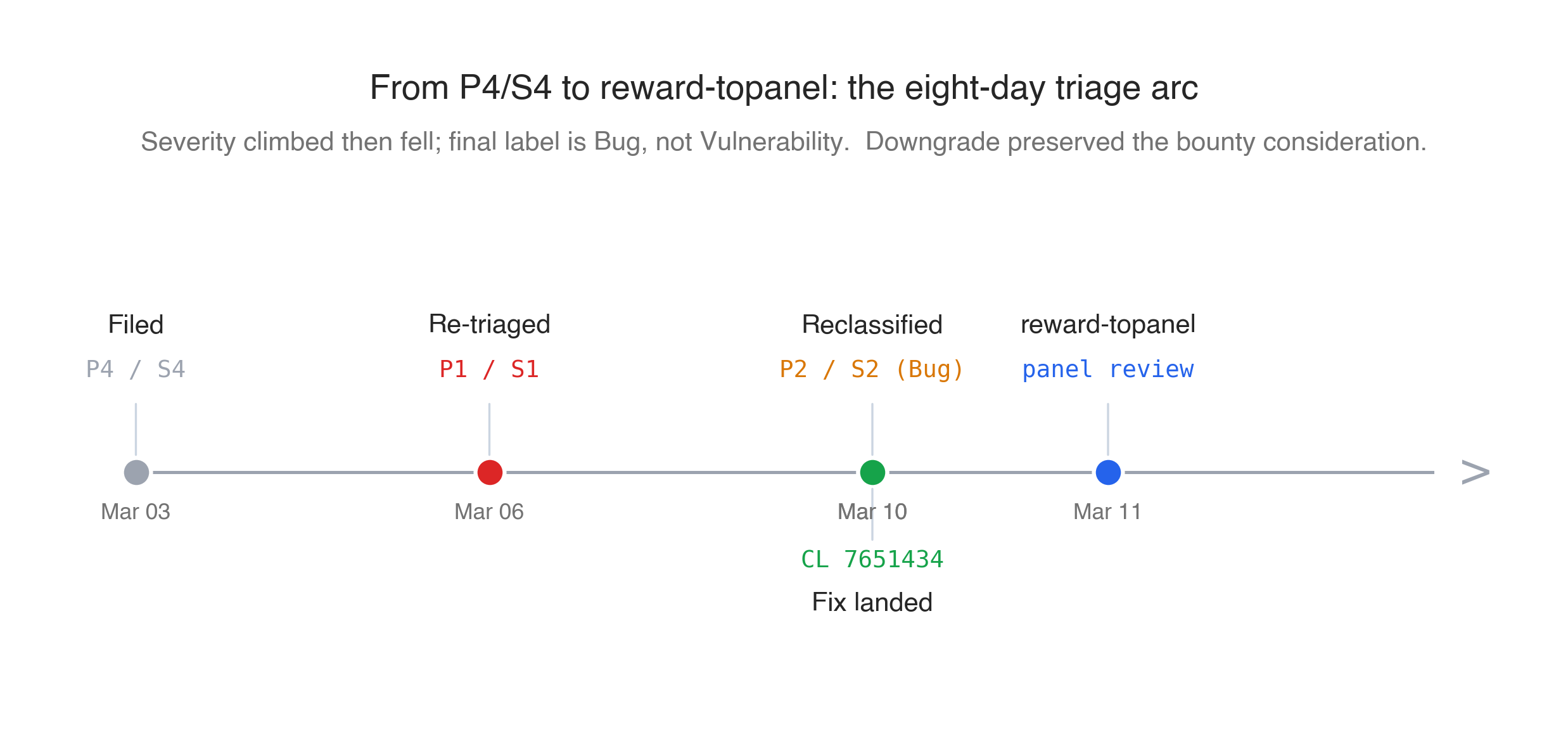
Reported on 2026-03-03 as Chromium issue #489577364. Fixed on 2026-03-10 by chromium-review CL 7651434, commit 2d111040. Triaged through P4/S4 → P1/S1 → P2/S2 Bug. Reclassified from Vulnerability to Bug by Victor Gomes (V8 core team) after analysis. Added to the reward-topanel hotlist on 2026-03-11 for VRP panel review anyway.
The reclassification is the most interesting part of the story. The bug was real; the security model around it was wrong in a way I want to write down.
Why Maglev
V8’s compilation pipeline has three tiers: Ignition (interpreter), Maglev (mid-tier optimizing compiler, enabled by default since Chrome 117), and Turbofan/Turboshaft (top-tier optimizer). Maglev sits between the bytecode interpreter and the heavy optimizer. It optimizes faster than Turbofan, generates less aggressive code, and is the tier most user-facing JavaScript actually runs in once warmed up.
Maglev’s graph builder is src/maglev/maglev-graph-builder.cc, about 18,000 lines at the time of audit. The file is a procedurally-organized translator from V8 bytecode to a sea-of-nodes-ish IR. Every JS-visible operation has a VisitFoo and often a TryReduceFoo for the inlined fast path. The fast paths are where the bugs live: each is making speculative assumptions about runtime types based on feedback collected during interpretation, and each has to thread the consequences of those assumptions through the rest of the function under compilation.
I picked Maglev because mid-tier JITs are a known fragile-by-class target — speculation contracts are hard to reason about cleanly, the recent CVE history (CVE-2024-0517, CVE-2024-4947, CVE-2024-6773, CVE-2025-5419, CVE-2025-10585) all hit JIT optimization layers, and Chrome’s VRP pays in five-to-six figures for the right primitives. The audited surface is mature; the unaudited surface is whatever logic landed in the last six months.
The audit workflow
I gave Claude maglev-graph-builder.cc and asked it to enumerate every RAII state-management scope class in the file. The pattern I was looking for: small classes with a constructor that overwrites builder state and a destructor that restores it. The audit hypothesis was that any save/restore-shaped class is exactly the kind of code that can subtly fail to save before it overwrites.
The model came back with roughly a dozen candidates, including the obvious ones: LazyDeoptResultLocationScope, LazyDeoptContinuationScope, EagerDeoptFrameScope, and a handful of Save*Scope classes. Most of them save into a default-initialized field, so even a missing constructor assignment falls back to a sensible value.
SaveCallSpeculationScope was the outlier. I asked the model to show me, side by side, every member field declared in the class, every place each field is read, and every place each field is written. The output was four lines that didn’t match: saved_mode_ had one read site (the destructor) and zero write sites in the constructor. The class definition declared it with no default member initializer.
That’s the bug. I went and read the file directly to verify the model wasn’t hallucinating a missing write, then read every caller of the scope class to confirm the destructor actually runs at the relevant points. Both held. The whole exchange took maybe forty minutes.

The bug
src/maglev/maglev-graph-builder.cc, lines 362-393, scoped class definition:
class V8_NODISCARD MaglevGraphBuilder::SaveCallSpeculationScope {
public:
explicit SaveCallSpeculationScope(
MaglevGraphBuilder* builder,
compiler::FeedbackSource feedback_source = compiler::FeedbackSource())
: builder_(builder) {
saved_ = builder_->current_speculation_feedback();
// BUG: saved_mode_ is NEVER assigned here.
SpeculationMode mode = MaglevGraphBuilder::GetSpeculationMode(
builder_->broker(), feedback_source);
if (mode != SpeculationMode::kDisallowSpeculation) {
builder_->reducer_.set_current_speculation_feedback(feedback_source);
builder_->current_speculation_mode_ = mode;
} else {
builder->reducer_.set_current_speculation_feedback(
compiler::FeedbackSource());
builder_->current_speculation_mode_ =
SpeculationMode::kDisallowSpeculation;
}
}
~SaveCallSpeculationScope() {
builder_->reducer_.set_current_speculation_feedback(saved_);
builder_->current_speculation_mode_ = saved_mode_; // reads uninitialized
}
private:
MaglevGraphBuilder* builder_;
compiler::FeedbackSource saved_;
SpeculationMode saved_mode_; // declared, never written before read
};The constructor assigns saved_ from builder_->current_speculation_feedback() (line 367), then writes to builder_->current_speculation_mode_ (lines 374 or 378-379). The destructor reads saved_ and writes it back — correct round trip for the feedback. It also reads saved_mode_ and writes that to current_speculation_mode_ — but saved_mode_ was never assigned.
SpeculationMode is a uint8_t-backed enum class with three values:
enum class SpeculationMode {
kAllowSpeculation = 0,
kDisallowBoundsCheckSpeculation = 1,
kDisallowSpeculation = 3,
};The notable thing about the enum is that the “safe” value kDisallowSpeculation is 3, not 1. A stack-allocated uint8_t that happens to be zero — by far the most common state of uninitialized stack memory — reads back as kAllowSpeculation. The interpretation of an uninitialized read as “speculation is fine, go for it” is not a worst-case theoretical concern; it’s the most likely concrete reading.
builder_->current_speculation_mode_ is checked at 30+ sites in the graph builder via CanSpeculateCall():
bool CanSpeculateCall() const {
return current_speculation_mode_ == SpeculationMode::kAllowSpeculation;
}The 30+ sites include type-specialized array operations (push, pop, at, forEach, map, filter), DataView typed access, integer overflow checks in Math.abs, string operations like charAt and charCodeAt, object property lookups, and several constructor paths. The flag controls whether the compiler emits a fast type-specialized version of each operation or falls back to a slow generic version.
The PoC
The scope is instantiated at six points in the graph builder: TryReduceBuiltin (line 11482), TryReduceFunctionPrototypeCall (line 10350), TryReduceFunctionPrototypeApplyCallWithReceiver (line 12186), BuildConstruct (line 13552), HasInstance (line 13948), and an array-iteration callback path (line 9156). Five user-facing language constructs reach those: f.call(...), f.apply(...), arr.forEach(...), new Array(...), and x instanceof Foo.
The PoC exercises all five with 50,000 warmup iterations each to push them through Maglev compilation:
function triggerViaCall(f, x) { return f.call(null, x); }
function triggerViaApply(f, x) { return f.apply(null, [x]); }
function triggerViaForEach(arr, cb) { arr.forEach(cb); }
function triggerViaConstruct(n) { return new Array(n); }
function triggerViaInstanceOf(o, c) { return o instanceof c; }
for (let i = 0; i < 50000; i++) triggerViaCall(Math.abs, -42);
for (let i = 0; i < 50000; i++) triggerViaApply(Math.abs, -42);
let s = 0; const add = x => { s += x; };
for (let i = 0; i < 50000; i++) { s = 0; triggerViaForEach([1,2,3], add); }
for (let i = 0; i < 50000; i++) triggerViaConstruct(10);
class Foo {} let foo = new Foo();
for (let i = 0; i < 50000; i++) triggerViaInstanceOf(foo, Foo);Build d8 with MSAN, run with --maglev --no-turbofan:
gn gen out/msan --args='is_msan=true is_debug=false v8_enable_maglev=true target_cpu="x64"'
autoninja -C out/msan d8
out/msan/d8 --maglev --no-turbofan poc.jsMSAN flags:
WARNING: MemorySanitizer: use-of-uninitialized-value
#0 MaglevGraphBuilder::SaveCallSpeculationScope::~SaveCallSpeculationScope()
src/maglev/maglev-graph-builder.cc:384
#1 MaglevGraphBuilder::TryReduceBuiltin(...)
src/maglev/maglev-graph-builder.cc:11495The fix is one line:
: builder_(builder) {
saved_ = builder_->current_speculation_feedback();
+ saved_mode_ = builder_->current_speculation_mode_;
// Only set the current speculation feedback if speculation is allowed.
SpeculationMode mode = MaglevGraphBuilder::GetSpeculationMode(
builder_->broker(), feedback_source);Save the old mode before overwriting it. That’s it. The V8 team’s landed patch is identical to my proposed fix.
The downgrade
The bug filed at P4/S4. Two days later it moved to P1/S1. A day after that, Victor Gomes (V8 core team, Maglev-adjacent) wrote up an analysis and moved it to P2/S2, reclassifying it from “Vulnerability” to “Bug.” The patch landed the same day.
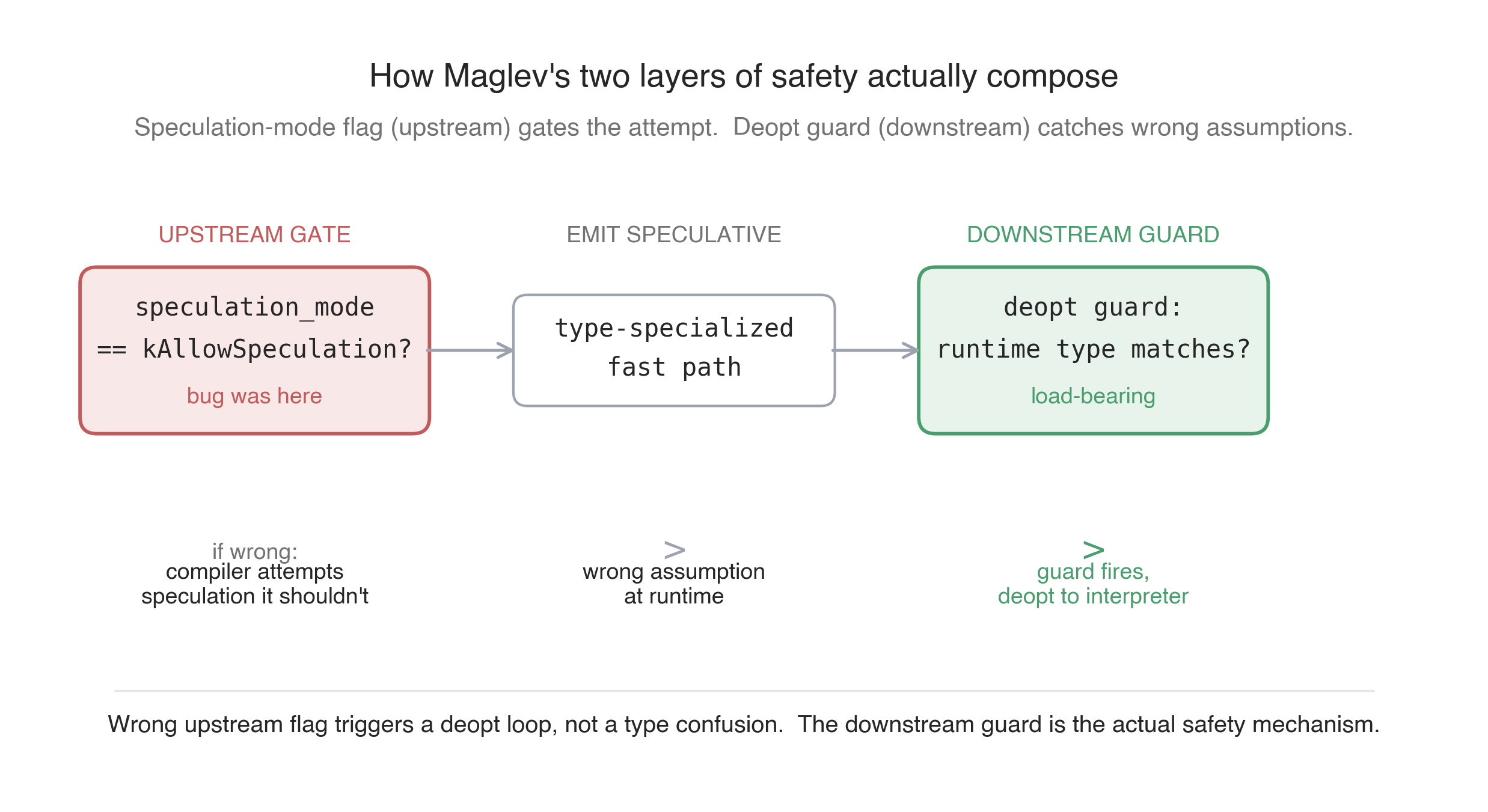
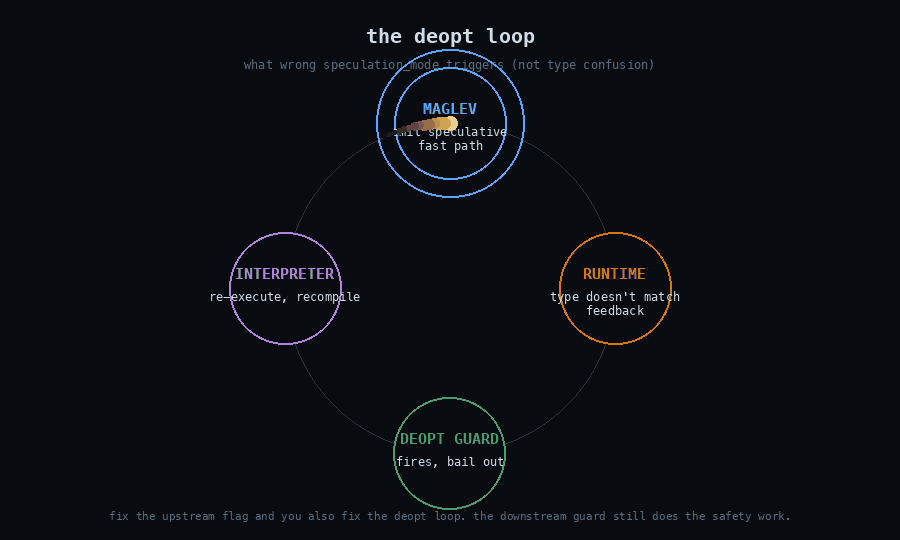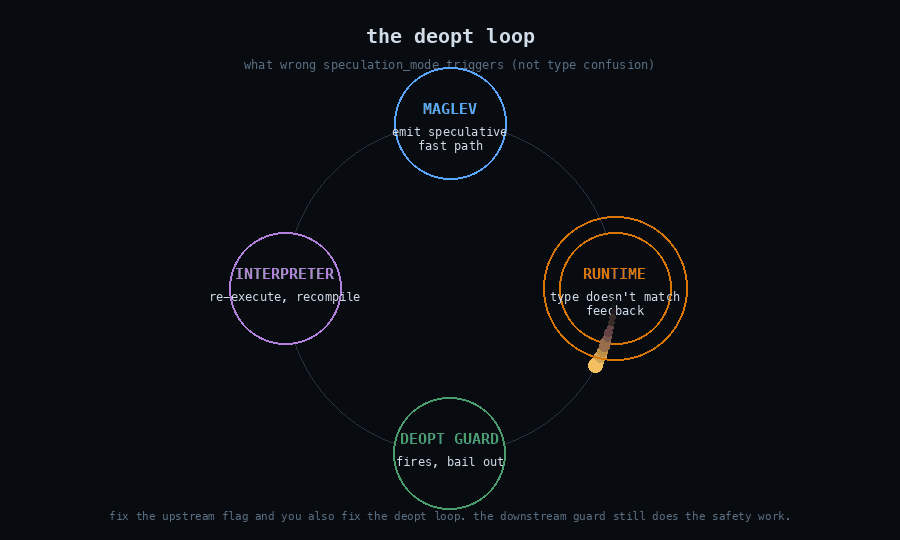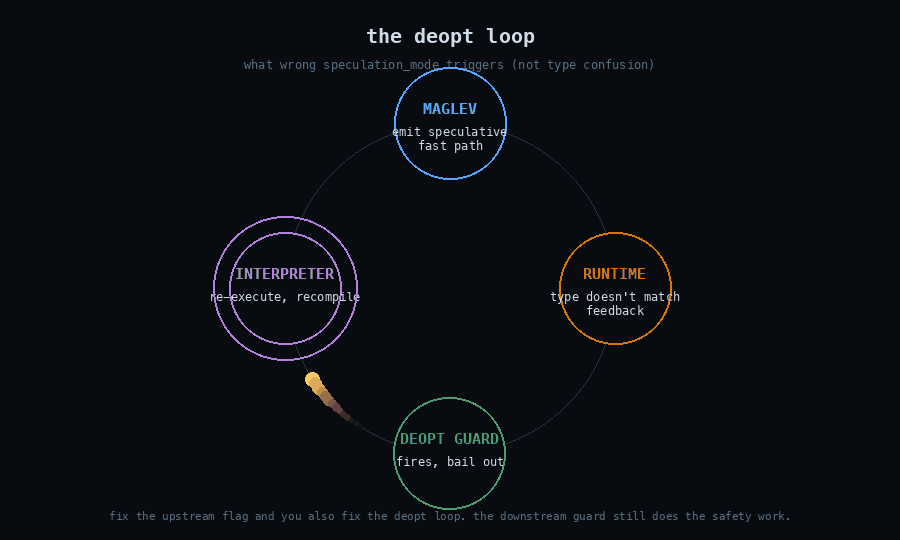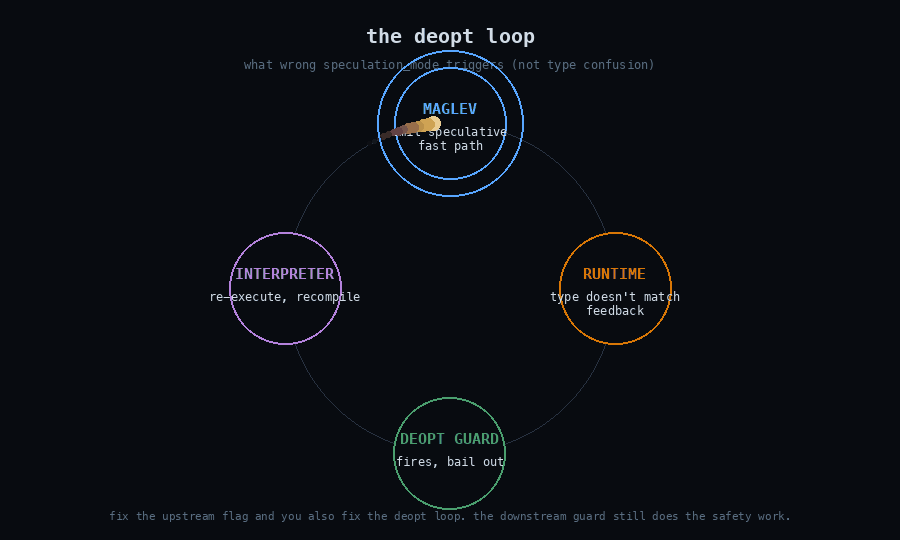
The reclassification reasoning, paraphrased from his comments: Maglev emits a deopt guard on every speculative operation. The speculation-mode flag controls whether the compiler will try to emit a speculative fast path. The guard inside the emitted fast path is what catches a wrong-type call at runtime and bails out to the interpreter. If current_speculation_mode_ happens to be kAllowSpeculation when it shouldn’t be — because of this uninitialized read — Maglev will optimistically emit a speculative version of an operation that previous feedback indicated should not be specialized. When that operation runs with a value of an unexpected type, the deopt guard fires, control returns to the interpreter, the function is reoptimized with corrected feedback, and execution continues. The visible consequence is a deopt loop, possibly a performance regression, not a type confusion that escapes into the runtime.
I want to read this carefully because the engineering claim is precise. The bug is a real undefined-behavior read with a real security-relevant decision downstream of it. But the question for exploitation is not “can I make the flag wrong?” — it’s “if the flag is wrong, can I make the emitted code execute on a value whose type contradicts the speculation, without the guard catching me?” The answer in the current Maglev pipeline is no, because the guard is the last word.
This isn’t a free pass. The reclassified-as-Bug label still got the issue onto the reward-topanel hotlist on 2026-03-11, which is the V8 team’s signal that the report has bounty merit despite the downgrade. Final reward is at panel discretion. But the impact framing in the original report was wrong, and I want to be clear about why.
What I had right and what I missed
What I had right: the bug exists, the trigger paths are real, the PoC exercises five distinct call sites, the proposed fix is the same fix the team landed, the reading of the enum gap (kAllowSpeculation = 0 being the dominant uninit value) is correct, and the audit workflow that found it generalizes.
What I missed: the speculation-mode flag isn’t the load-bearing safety layer for this class of optimization. Maglev’s design includes the speculation flag as an upstream gate (“should I try this?”) and the deopt guard as a downstream check (“did the runtime values match what I assumed?”). Two layers. The bug was in the upstream gate. The downstream check is what actually preserves type safety, and it doesn’t depend on the upstream gate being correct.
There’s a generalizable lesson here that I want to bank. When auditing a security-critical decision in a JIT or any layered system, the question isn’t “is this decision correctly made?” It’s “if this decision is wrong, what catches it downstream?” If nothing catches it, you have a vulnerability. If something does, you have a bug — possibly an important one, possibly worth fixing for code-quality reasons or defense-in-depth or LTO-stability reasons, but not a vulnerability in the same sense.
The defenses-in-depth view turns the audit question from “where is the unguarded check?” into “where is the unguarded layer?” Those aren’t the same question, and the former finds bugs that the latter wouldn’t have found, but it also produces false positives on the impact axis. I had a real bug. The impact framing inflated past the actual primitive.
I think the right calibration is: when you find a bug that would be exploitable if its guard layer didn’t exist, file it, document the guard layer’s role explicitly in the impact section, and let the vendor decide how much weight the guard carries. That gives them the full picture without claiming impact you can’t demonstrate. I didn’t do that on this one. Next time I will.
Why audit Maglev anyway
The downgrade is a useful corrective, not an argument against auditing this layer. A few reasons.
First, defense-in-depth audits land. The V8 team did not say “this isn’t worth fixing.” They said “this isn’t a vulnerability, and we are fixing it anyway, and we are putting it on the reward panel.” Chrome’s bounty program rewards code-quality and latent-safety reports, not only exploitable primitives. The reclassification cost me an order of magnitude on expected payout, not the payout itself.
Second, the layer that catches the bug today might not catch it tomorrow. Victor Gomes’s analysis is correct under the current pipeline. If a future Maglev change adds a CanSpeculateCall() check in a code path that doesn’t subsequently emit a deopt guard — for instance, a control-flow decision that affects which IR nodes get built but isn’t checked at runtime — the same uninitialized read becomes exploitable. The patch closes that future regression too. Audit-by-spec at this layer is a one-time cost that pays out across the codebase’s lifetime.
Third, LTO and PGO can interact with undefined behavior in ways the local compiler doesn’t. A read of uninitialized memory is undefined behavior at the language level, and aggressive whole-program optimization is permitted to assume undefined behavior never happens. The destructor’s current_speculation_mode_ = saved_mode_ could legally be optimized to a no-op store — at which point the constructor’s earlier write to current_speculation_mode_ persists past the scope’s lifetime, breaking the save/restore invariant in the other direction. That’s a more interesting failure mode than the uninit-read direction, and it’s the kind of thing that won’t show up in MSAN runs but will show up in production builds with LTO enabled. The fix closes both directions.
The audit workflow, generalized
The pattern that produced this finding is enumeration-of-shape, not enumeration-of-code. The shape was “RAII scope class with member fields whose lifetime is bounded by the scope.” The code was secondary; what mattered was identifying a class of constructs in the file and then asking, for each, whether the save/restore invariant holds. Out of a dozen candidates, eleven were correct. One wasn’t.
The model is good at this kind of work. “Find every class in this file that matches pattern X” is exactly the request that doesn’t degrade across 18,000 lines. It doesn’t get bored, it doesn’t skip files, and it doesn’t lose track of what it’s looking for the way a human reading sequentially does.
The model is bad at the next step: “is this exploitable?” That’s a question about the whole system, not the local code. The Victor Gomes downgrade is a clean example: the local code is broken, the global system catches it, only the global view answers the impact question. I had to file the report and wait for a domain expert to surface the global view. I didn’t have it on my own. That’s the persistent gap between LLM-assisted enumeration and judgment, and it’s the gap I keep paying for in calibration.
If you want to reproduce the workflow: pick a file. Ask for an enumeration of a structural pattern. Verify each candidate yourself by reading the code. File only what you can defend without the model. Treat the model’s confidence as orthogonal to ground truth.
Disclosure timeline
- 2026-03-03: Reported to Chromium VRP as #489577364. Initial triage P4/S4.
- 2026-03-06: Re-triaged to P1/S1 after security team review.
- 2026-03-10: Victor Gomes posts analysis, reclassifies to P2/S2 Bug. Fix CL 7651434 lands the same day as commit
2d111040. - 2026-03-11: Added to
reward-topanelhotlist. - 2026-05-15: This writeup.
The fix is in V8 head and will ride into the next Chrome stable channel rollout.
PoC and detailed writeup are in my research archive; the fix CL and the issue tracker entry are linked above. Originally published at tomryan.dev.
How this was written
This post was drafted from my notes by an AI model and then edited by me. The reasoning, decisions, and corrections are mine; the prose started from a machine. The underlying technical work this post describes is real.
Licensed CC-BY-4.0.