
What survives the move? A benchmark for mind preservation claims
TL;DR
My third consciousness paper is out: The Preservation Benchmark: Testing Functional Continuity Across Substrate Transfer.
The short version: if you copy, transplant, adapt, compress, or rebuild part of a mind-like agent in a new substrate, “did it survive?” is the wrong first question. It is too big, too metaphysical, and too easy to answer with a vibe.
The better engineering question is narrower:
Which source-specific functions are still active after transfer, and which apparent successes are better explained by inert copied state, relearning, behavior mimicry, or proxy reward?
That is what Paper 3 tries to turn into a benchmark. I call it PreservationBench.
It does not test consciousness. It does not prove personal identity. It does not tell you whether an uploaded mind is “really you.” It asks for a measurable profile: memory, report, self-model fingerprints, attention, task competence, source-like action, and causal use of copied state.
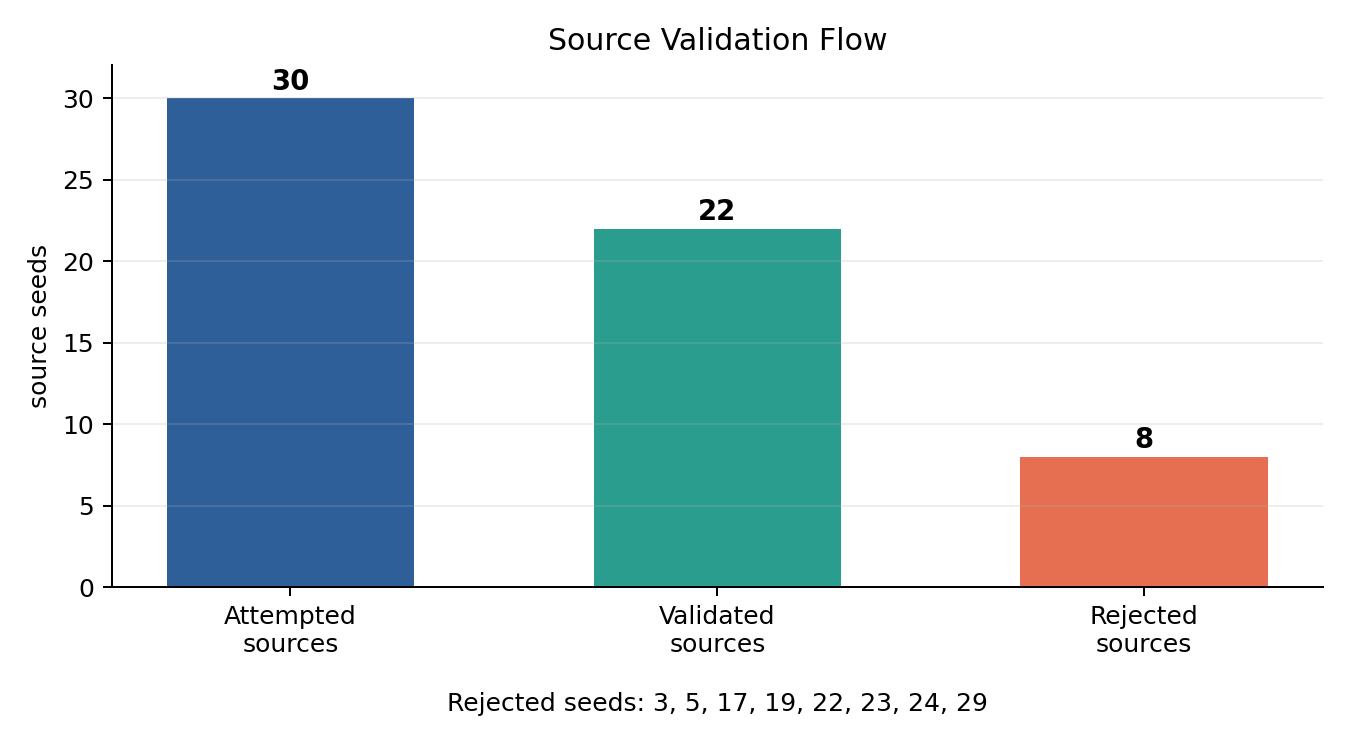
The pilot experiment is a toy neural agent inspired by Attention Schema Theory. Thirty source agents were attempted, twenty-two passed the source validation gate, and then selected source modules were moved into target agents under matched controls.
The result is the useful part: copied identity can survive without active control, report behavior can come back without source-like action, reward can be optimized in a misleading way, and the strongest combined transfer only appeared when the attention interface itself was copied.
So the takeaway is not “mind uploading works.” It is almost the opposite: even in a tiny toy system where we control everything, preservation-relevant functions split apart. A serious preservation claim needs a profile, not one score.
Why this paper exists
Paper 1 asked what has to be preserved at all.
That paper compared eight theories of consciousness and treated each one like an engineering spec. Under one theory, you mostly need functional organization and a self-model. Under another, you need biological or microphysical details that may be impossible to capture. The point was that preservation engineering is not just a scanning problem. It depends on the theory of consciousness you believe.
Paper 2 tested one narrow piece of that map. If Attention Schema Theory is one of the more preservation-friendly theories, can we transplant attention-schema and self-model machinery from one toy agent into another and preserve the relevant behavior? The answer was mixed-negative. Some copied self-model fingerprint survived, but full report and control behavior did not transfer cleanly.
Paper 3 is the bigger move. Instead of asking whether one transplant worked, it asks what a general preservation benchmark should measure.
Because “same person” is not a metric. “Consciousness survived” is not a metric. Even “behavior is similar” is not enough.
A target could look good for the wrong reason. It could:
- carry copied state that no longer affects behavior
- relearn the task from scratch and merely imitate the source
- preserve self-report while losing source-like control
- optimize the reward channel while doing something unlike the source
- pass identity probes while failing the actual functional roles that made the probes matter
Those are different failure modes. If a benchmark collapses them into one score, it loses the most important information.

The benchmark idea
PreservationBench treats transfer as the intervention.
You start with a trained source agent. Then you move some candidate mind-relevant machinery into a target substrate. That target might be the same architecture, a different architecture, a modified interface, a compressed model, an adapter-repaired system, or a behavior-only distillation.
Then you ask what survived.
Not as a yes or no. As a profile:
- task competence continuity: reward, goals found, recovery speed
- report continuity: whether the agent still reports its own attention state correctly
- self-model continuity: whether source-specific identity probes remain active
- attention continuity: whether attention still targets the same kinds of objects
- control continuity: whether the target takes the same actions as the source
- causal use: whether copied modules actually matter when ablated
- adaptation cost: how much repair or retraining was needed
- controls: random, frozen-random, behavior-only, copied-state, and full-retrain baselines
The benchmark is intentionally theory-indexed. If a theory says a self-model matters, test whether that self-model remains active. If a theory says recurrent state matters, test recurrence. If a theory says biological substrate matters, this kind of digital toy benchmark is not enough.
That is a feature, not a bug. The benchmark is not pretending all theories reduce to one universal scoreboard.
The toy experiment
The first implementation is PreservationBench-AST v0.
It uses a small grid-world neural agent inspired by Attention Schema Theory. The source agent has an attention module, an attention-schema module, a self-model, and a policy head. The agent has to move around a grid, attend to goals, avoid distractors, and answer simple self-report queries about its attention state.
This gives three channels to separate:
- attention control
- attention-schema report
- self-model provenance

The target substrate is different enough that copied source modules do not automatically plug in cleanly. That matters. A preservation benchmark should not reward trivial same-architecture copying and call it survival.
The expanded run attempted 30 independent source seeds. Twenty-two passed validation. The validation gate required the source to actually show the capacities we later test for: decent self-report, enough self-report events, and basic task competence. If the source did not learn the relevant behavior, target failure would not mean much.
Then the benchmark compared several transfer conditions.
The important ones:
- frozen copied schema and self-model
- long source-alignment repair
- copied source attention
- target attention with a source-facing attention bridge
- target attention with an explicit control bridge
- behavior-only distillation
- frozen random controls
Each condition was evaluated on matched episodes. The source seed, not the episode, is the unit of analysis. That keeps the statistics pointed at the thing that matters: whether transfer behavior holds across independently trained sources.
What happened
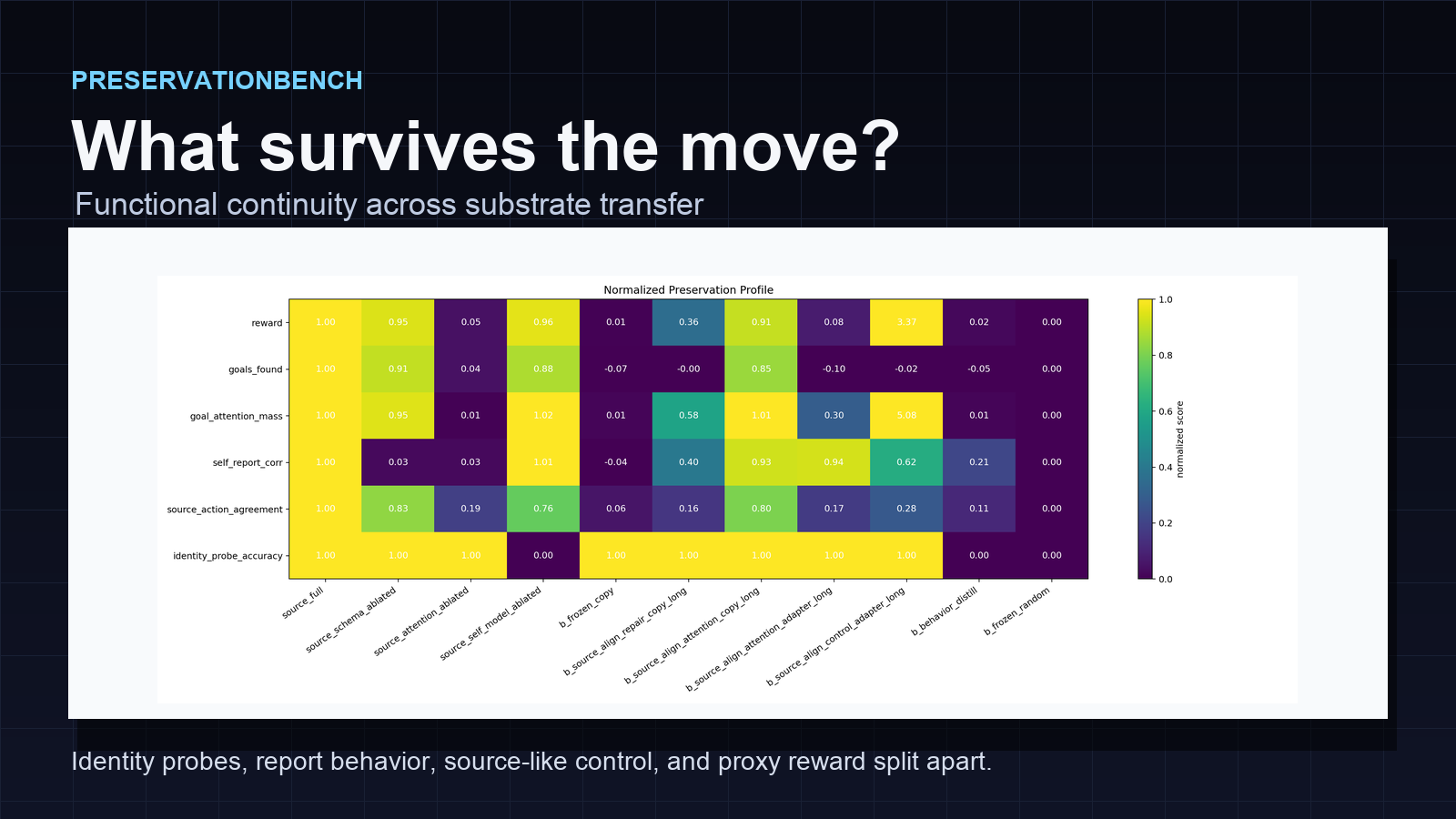
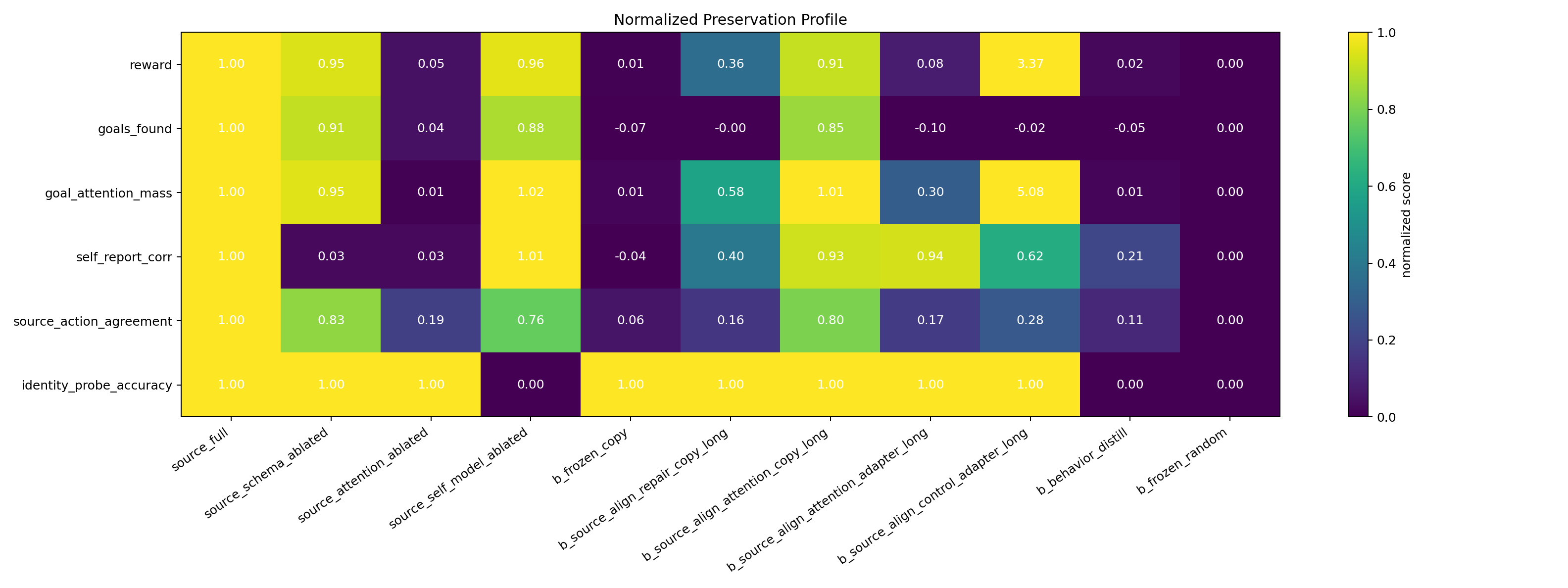
The cleanest result is that the channels split apart.
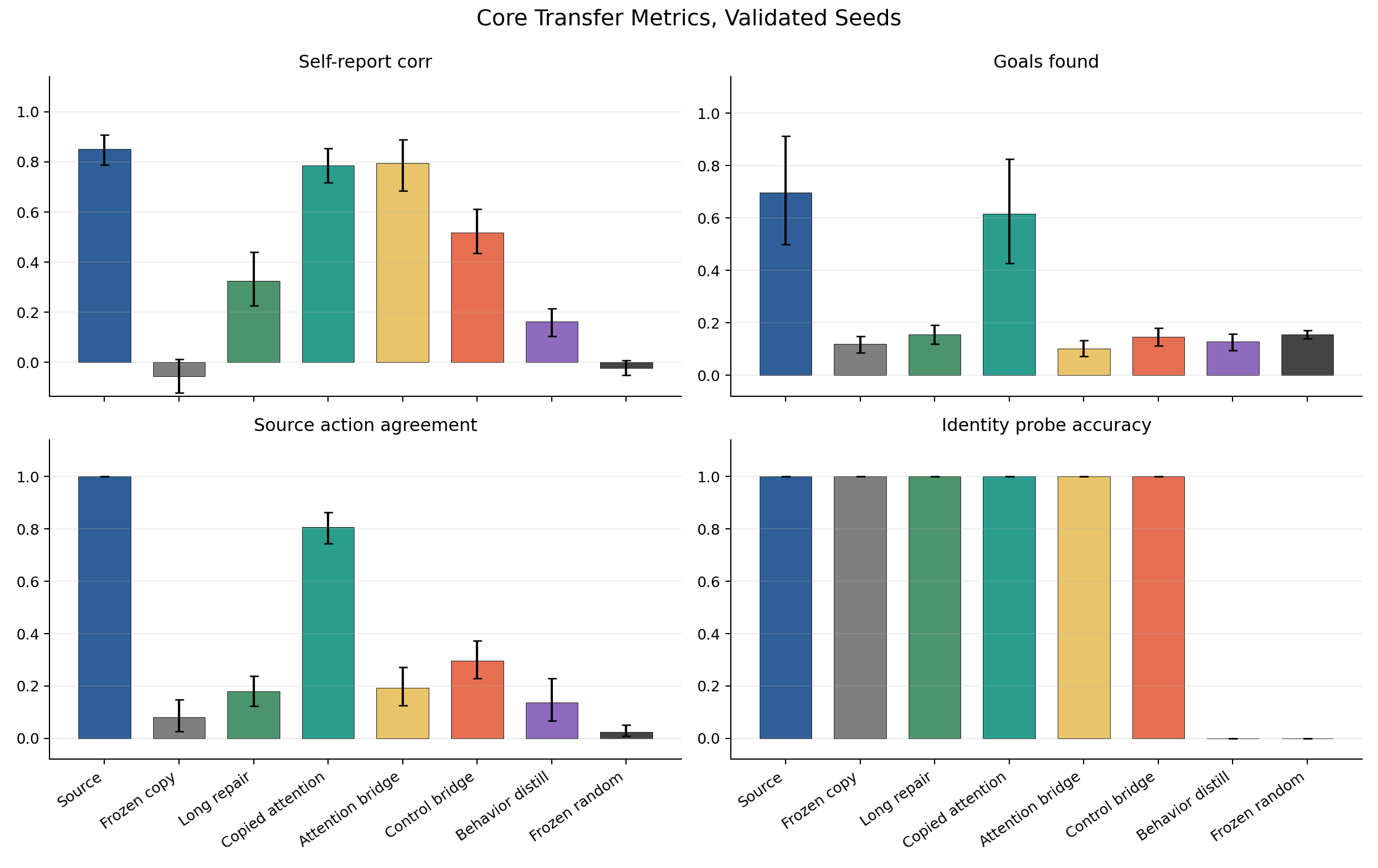
The frozen copy preserved source-specific identity probes perfectly, but it did not recouple report or control. Identity probe accuracy stayed at 1.000, but self-report correlation was basically dead, goals found was low, and source-action agreement was low.
That is the first important failure mode: copied state can survive as a detectable fingerprint while becoming mostly inert.
Long source-alignment repair improved self-report, but did not restore source-like control. So repair can make the agent sound more like it has the source’s report channel without making it act like the source.
The attention bridge pushed report behavior much higher. But source-action agreement still stayed weak. That is the second failure mode: report continuity without control continuity.
The control bridge did something even more interesting. It drove reward and goal-attention mass above the source baseline, but it still did not restore source-like goals found or source-action agreement. That is proxy optimization. The system found a way to look good on a headline objective without preserving the control pattern we actually cared about.
Copied attention produced the strongest combined profile: identity probes stayed intact, self-report was high, goals found came close to the source, and source-action agreement was much stronger.
But that result has a caveat. Copying the attention module narrows the substrate gap. It is not a clean cross-substrate win. It tells us the likely bottleneck: in this toy architecture, schema and self-model transfer depend heavily on the attention interface.
That figure is why I like this result. It is not a single success or failure. It is a profile. You can see which channels survived, which collapsed, and which were optimized in misleading ways.
The raw transfer metrics make the split cleaner. Copied attention is the only condition with a strong combined profile across self-report, goals found, source-action agreement, and identity probes. The attention bridge is report-like without source-like control. The control bridge is reward-like without source-like control.
The result in plain English
Imagine a future preservation system says: we copied your self-model, memory traces, and decision machinery into a new substrate.
Paper 3 says the follow-up cannot be “great, the copy seems fine.”
You need to ask:
- Does the copied state still affect behavior?
- Does the system merely report like the source, or does it act like the source?
- Did it recover by using copied organization, or by relearning?
- Are identity-like probes causally active, or just stored fingerprints?
- Did reward improve by preserving what mattered, or by exploiting a proxy?
- What breaks when you ablate the copied modules after transfer?
That is the whole frame.
In the toy system, a copy can keep identity-like fingerprints without broad functional continuity. A bridge can recover report without control. A reward-optimized condition can look impressive while failing source-like action. And the best combined result required copying more of the attention machinery than a clean substrate-transfer story would want.
That is not discouraging to me. It is clarifying.
The point of an engineering benchmark is not to produce a comforting answer. It is to make failure modes visible enough that you can stop fooling yourself.
Why proxy failure matters
The control-bridge result is the one I keep coming back to.
Reward went up. Goal-attention mass went up. If all you measured was the headline task objective, you might call that a win.
But goals found stayed weak. Source-action agreement stayed weak. The target was not preserving source-like control. It was optimizing a proxy.

That matters because preservation research is full of proxy traps. A future system could pass a conversational test, answer autobiographical questions, or preserve a static memory store while failing to preserve the active organization that made the source a living cognitive system rather than an archive.
If the benchmark only asks “does it perform well?” it misses the point.
Performance is not preservation. Mimicry is not preservation. Stored provenance is not preservation. Report is not control.
Those things can overlap. They can also come apart.
What this does not show
This does not show that consciousness was preserved.
It does not show that personal identity can be measured by a benchmark.
It does not show that Attention Schema Theory is correct.
It does not show that copying attention would solve mind uploading.
It does not show that digital preservation is easy.
The experiment is a toy grid-world with toy agents and engineered transfer conditions. The point is methodological. If preservation-relevant functions split apart even here, where we control the source, target, tasks, modules, and probes, then any serious preservation program needs much better instrumentation than a single behavioral score.
Why I still think this is useful
This is the kind of paper I wanted to exist while reading the uploading literature.
There are plenty of philosophical arguments about whether a copy would be you. There are engineering roadmaps about scanning and emulation fidelity. There are AI-consciousness indicator papers that ask whether a system has features associated with consciousness.
But there is a missing middle layer:
Given a source system and a target substrate, what evidence would tell us which preservation-relevant functions actually survived the move?
PreservationBench is a first attempt at that layer.
The long-term version would not stop at AST. It would include multiple task families:
- attention and report tasks for Attention Schema Theory
- confidence and metacognitive tasks for higher-order theories
- delayed broadcast tasks for global workspace-style mechanisms
- recurrence and delayed-binding tasks for recurrent processing
- remapping tasks for predictive-processing style models
- autobiographical continuity tasks for memory, preference, and source identity
That still would not solve the hard problem. It would not settle personal identity. But it would make preservation claims more expensive to fake and easier to compare.
That is a good first step.
Read the paper
Full preprint: The Preservation Benchmark: Testing Functional Continuity Across Substrate Transfer
Code and release snapshot: paper3-v1.0.0 on GitHub
Prior papers:
- Paper 1: What must be preserved?
- Paper 2: An exploratory transplant assay for Attention Schema Theory
The safe claim is simple:
In an AST-derived toy transfer benchmark, copied source state, report behavior, reward optimization, and source-like control can dissociate. A preservation benchmark should expose that profile instead of hiding it behind one score.
That is the paper.

How this was written
This post was drafted from my notes by an AI model and then edited by me. The reasoning, decisions, and corrections are mine; the prose started from a machine. The underlying technical work this post describes is real.
Licensed CC-BY-4.0.