
Finding an io_uring OOB read with Claude, and the limits of LLM-assisted kernel auditing
TL;DR
io_uring’s 128-byte SQE submission path on IORING_SETUP_SQE_MIXED rings validates the logical SQ head position rather than the physical SQE index returned by sq_array. An unprivileged user can route a 128-byte op to the last physical SQE slot and trigger a deterministic 64-byte OOB read past the SQE array, every call to io_uring_enter(), no race.
Assigned CVE-2026-43442. Fixed in 6f02c6b19603, authored by me and merged by Jens Axboe on 2026-03-11, with a liburing regression test in a35e4943ec95. Backported for Linux 6.19.9 as 1f794f9bed3e by Greg Kroah-Hartman. Public PoC and full writeup: gist.
Why io_uring
io_uring is well-trodden ground. Jann Horn, Aleksey Mardanov, Awarau, FizzBuzz101. There’s a deep public catalog of writeups, and the maintainers have hardened the obvious surfaces accordingly. So why pick it now?
Two reasons. The first is that io_uring keeps shipping. New features land in mainline almost every release cycle. Each new feature is a new boundary check, a new index calculation, a new lifetime to track, in code that has by definition not been read at the same depth as the rest of the subsystem. The audited surface is mature; the unaudited surface is whatever landed last quarter.
IORING_SETUP_SQE_MIXED was one of those new features. Introduced in 6.19 by 1cba30bf9fdd, it lets you mix 64-byte and 128-byte SQEs in the same ring, which is useful when you want the ergonomics of a single submission queue while still issuing the occasional URING_CMD128. Most of the relevant checks live in io_init_req(). That’s where I started.
The second reason: io_uring bugs in the submission path tend to be deterministic primitives, not races. SQE submission runs on the calling thread, not in a worker. An index-calculation bug here isn’t a TOCTOU you have to win, it’s an OOB you trigger every time. That makes the work-to-defensible-finding ratio better than for, say, the audit-by-fuzzing pattern on a worker-heavy subsystem.
The audit workflow
Specifically: I gave Claude io_uring/io_uring.c (about 3700 lines at the time of the audit) and asked it to enumerate every place a user-controlled index gets used to dereference into a kernel buffer along the submission path. Roughly twenty candidates came back. Most were bounded correctly. head < sq_entries, kbuf->bid < kbuf->nbufs, the usual.
Two were not. The first was the sq_array indirection in io_get_sqe(). I asked the model to walk me through, in plain English, what physical SQE index the path actually dereferences for a 128-byte operation on an SQE_MIXED ring. The answer started fine: sq_array[head & mask] is user-controlled, the bounds check at head >= ctx->sq_entries correctly handles a 64-byte op, the 128-byte op consumes two slots. Then it caught the discrepancy: the boundary check intended to prevent a 128-byte op at the ring’s last slot was checking cached_sq_head, not the physical index returned by sq_array. The two are decoupled the moment sq_array is in play.
That’s the bug. The logical-position check passes, the physical index lands at the last slot, and io_uring_cmd_sqe_copy() does its 128-byte memcpy, reading 64 bytes past the SQE array.
Maybe two hours of back-and-forth, including a detour to liburing source to understand the user-side setup, and another to confirm IORING_SETUP_NO_SQARRAY is opt-in (which means most rings are vulnerable). I knew the io_uring submission path well enough to follow each step. I would not have seen this myself in 3700 lines on a first read.
The waitid false positive
The second candidate was a waitid signal_struct lifetime issue. The model was confident the lifetime was broken. io_req_track_inflight() isn’t called in the waitid prep path, it said, so signal_struct could be freed under an in-flight request. It produced a plausible-sounding race window. I almost filed a maintainer report.
What was wrong: task_struct->usage references already keep signal_struct alive through the relevant window. The reference threading isn’t on signal_struct directly; it’s transitive through the task. The model had the local code right and the systemic invariant wrong, which is the failure mode where it sounds most authoritative. The per-function reading is correct, the cross-file invariant is invisible.
I caught it by re-reading kernel/exit.c and kernel/signal.c and include/linux/sched/signal.h until the lifetime argument fell apart. Then I went back to the model with what I’d found and it agreed, pleasantly, that yes, the bug wasn’t real. Easy agreement was its own warning sign.
I want to lead with this because the pattern matters: confident-sounding model output is not evidence. Treat it like a lead, run it down yourself. If I’d shipped that maintainer report, I’d have wasted a kernel maintainer’s time and learned the lesson the loud way.
The bug
The io_uring submission path takes a logical SQ head, remaps it through sq_array to a physical SQE index, and dereferences sq_sqes at that physical position:
/* io_uring/io_uring.c, io_get_sqe() */
unsigned head = ctx->cached_sq_head++ & mask;
head = READ_ONCE(ctx->sq_array[head]);
if (unlikely(head >= ctx->sq_entries))
return false;
*sqe = &ctx->sq_sqes[head];The head >= ctx->sq_entries check is correct for a 64-byte operation: any physical index in [0, sq_entries) points at a valid 64-byte SQE. For a 128-byte operation on an SQE_MIXED ring, the valid range is one slot smaller. The operation needs two consecutive 64-byte slots, so the maximum starting physical index is sq_entries - 2.
The check intended to enforce that lives in io_init_req():
/* io_uring/io_uring.c, io_init_req() */
if (def->is_128 && !(ctx->flags & IORING_SETUP_SQE128)) {
if (!(ctx->flags & IORING_SETUP_SQE_MIXED) || *left < 2 ||
!(ctx->cached_sq_head & (ctx->sq_entries - 1)))
return io_init_fail_req(req, -EINVAL);The third clause, !(ctx->cached_sq_head & (ctx->sq_entries - 1)), checks whether the current logical head is at position 0 of the ring, the wrap boundary. For an IORING_SETUP_NO_SQARRAY ring, where logical and physical indices are identical, this is sufficient.
But when sq_array is in use, logical and physical decouple. An attacker writes sq_array[N] = sq_entries - 1 for some logical position N that isn’t 0. The 128-byte operation submitted at logical position N passes the logical-position check, then gets routed through sq_array to the last physical SQE slot. io_uring_cmd_sqe_copy() then runs:
/* io_uring/uring_cmd.c */
memcpy(ac->sqes, ioucmd->sqe, uring_sqe_size(req)); /* 128 bytes */The source pointer is &sq_sqes[sq_entries - 1]. The first 64 bytes are the legitimate SQE; the second 64 bytes are whatever lives in the next page of the direct map.
Exploit primitive
What this gives you: a 64-byte read past the SQE array into adjacent kernel memory, deterministically, from unprivileged userspace, every call. No race, no spray-and-pray, no kernel-config dependency beyond having IORING_SETUP_SQE_MIXED available and not opting into IORING_SETUP_NO_SQARRAY.
The trigger:
sq_array[0] = 0 /* NOP at physical slot 0 (anchor) */
sq_array[1] = sq_entries - 1 /* URING_CMD128 at last physical slot */
sq_array[2] = 1 /* consumed by 128-byte op's second slot */
io_uring_enter(fd, 3, ...);The URING_CMD128 op kicks io_uring_cmd_sqe_copy(), which performs the OOB memcpy. The CQE for the URING_CMD128 op returns -EOPNOTSUPP because the test fd (a pipe) doesn’t actually support uring_cmd, but -EOPNOTSUPP confirms the path executed all the way through io_uring_cmd_sqe_copy(). The 128-byte memcpy already ran by the time the operation was rejected.
Where do the 64 OOB bytes land? The SQE array is allocated via alloc_pages (one page for sq_entries=64). The OOB read goes into the next page in the direct map. What’s there depends on page allocator state, but a real exploit chain would shape the surrounding allocations: spray, free, allocate the SQE array, repeat. The PoC doesn’t go that far. It stops at proving the read happens. The primitive is one half of an info-leak chain.
PoC source: sqe_mixed_oob_v2.c.
Why KASAN doesn’t catch it
The SQE array uses alloc_pages (order-0 for sq_entries=64). KASAN tracks page-allocator allocations at page granularity, not slab granularity, so an OOB read into the adjacent direct-map page passes; there’s no shadow byte saying that range is invalid. A kmalloc-based allocation with KASAN slab quarantine would have caught this immediately. io_uring’s choice to use raw page allocations for the SQE ring is the right call for performance, but it puts this class of bug below KASAN’s radar.
I bring this up because part of the reason to audit code by hand (or by model) is precisely to find what dynamic instrumentation can’t.
The patch
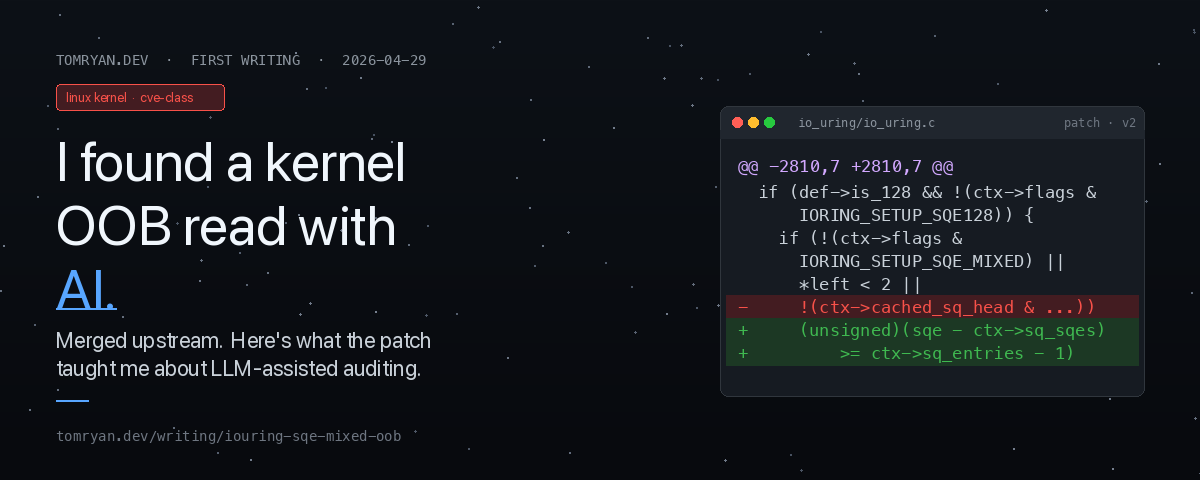
Jens Axboe’s fix replaces the logical-position check with a physical-index check derived directly from the SQE pointer:
if (!(ctx->flags & IORING_SETUP_SQE_MIXED) || *left < 2 ||
- !(ctx->cached_sq_head & (ctx->sq_entries - 1)))
+ (unsigned)(sqe - ctx->sq_sqes) >= ctx->sq_entries - 1)sqe - ctx->sq_sqes is the actual physical index. The SQE pointer was already resolved through sq_array by io_get_sqe(), so the pointer arithmetic reads off the physical position regardless of whether sq_array was involved. One line.
I’d originally proposed adding a separate physical-index check alongside the existing logical check. Caleb Sander Mateos pointed out that the physical check subsumes the logical one. The logical-position check was only catching the wrap case, which the physical check handles too. Keith Busch suggested folding it into the existing conditional. The maintainers’ final form is cleaner than my v1, and that’s the value of a real review thread: I’d have shipped two checks where one would do.
Greg Kroah-Hartman picked the fix into the 6.19 stable series as 1f794f9bed3e, released in 6.19.9. That’s the right call given the primitive: deterministic, unprivileged, on a hot path, no mitigation between trigger and OOB read.
Disclosure timeline
- 2026-03-08: Reported to
security@kernel.orgwith PoC and writeup. - 2026-03-09: Greg KH and Jens Axboe responded the same day. Jens noted the bug isn’t particularly nefarious (6.19+ only, narrow user base for SQE_MIXED), asked me to resend publicly to
io-uring@vger.kernel.org. v1 patch sent. - 2026-03-09: v2 patch sent incorporating review feedback from Caleb Sander Mateos and Keith Busch.
- 2026-03-11: Kernel patch
6f02c6b19603, authored by me, merged by Jens Axboe. - 2026-03-11: liburing regression test
a35e4943ec95applied by Jens Axboe. - 2026-03-19: Backport for Linux 6.19.9 as
1f794f9bed3eby Greg Kroah-Hartman. - 2026-04-29: This writeup.
- 2026-05-08: Published as CVE-2026-43442.
The full v1 to v2 thread is on lore.kernel.org if you want to read the reviewer feedback.
What LLM-assisted kernel auditing is and isn’t
I don’t claim kernel-internals depth. I’ve read enough io_uring to follow review threads, and I’d lose a debate with Jens Axboe in three messages. What I do have is a model that will read a thousand lines of C without getting bored, and the patience to verify what it tells me.
What the model is good at:
- Enumerating. “List every dereference of a user-controlled index into a kernel buffer in this 8000-line file.” It will not skip files, miss callers, or get tired around hour three.
- Generating PoC scaffolds from a hypothesis. I describe a trigger; it produces a syscall sequence I can debug. Half of it will be wrong, but the half that’s right saves me an hour of typing.
- Re-reading dense code aloud. This sounds dumb but it’s where most progress happened. I’d ask it to walk me through a function’s invariants in plain English; I’d hear something that didn’t fit my mental model; I’d dig in. The hit rate on that pattern is high.
What the model is bad at:
- Object lifetime reasoning across files. The waitid case is the canonical example. Local code looks broken; systemic invariant says it isn’t. The model doesn’t carry the systemic invariant.
- Distinguishing “looks suspicious” from “is exploitable.” Suspicious is cheap. Exploitable is the work. The model won’t tell you the difference; it will produce both with the same confident tone.
- Anything that requires holding more than a few files of state in working memory at once. It compresses; it doesn’t track. By the time you’ve spelunked through six files in one session, the state from the first three is unreliable.
The honest summary is that I’m faster on mechanical sweeps and slower on judgment than I would be without it. The model shifts the bottleneck to taste, verification, and pattern recognition, but it doesn’t remove it. This bug got real because I treated the model’s confident output as a lead I had to verify, not as the answer. The waitid non-bug got caught for the same reason.
If you want to reproduce this workflow: pick code that’s recent, narrow your audit surface to a single subsystem, prompt for enumeration not judgment, and treat every model assertion as a lead to verify rather than a finding to report. The judgment is yours. The model just makes the mechanical part faster.
PoC and the longer technical writeup: gist. The patch: 6f02c6b19603. The official record: CVE-2026-43442.

How this was written
This post was drafted from my notes by an AI model and then edited by me. The reasoning, decisions, and corrections are mine; the prose started from a machine. The underlying technical work this post describes is real.
Licensed CC-BY-4.0.